Stream-K
stream-k 抛弃了 slice-k 和 split-k 以任务为中心的划分逻辑,而是变成了以计算资源为核心的分配任务方式,使得每个 SM 的任务量基本相当。
这是论文中的算法3,会在算法5中用到。

算法5是 stream-k 的具体实现。

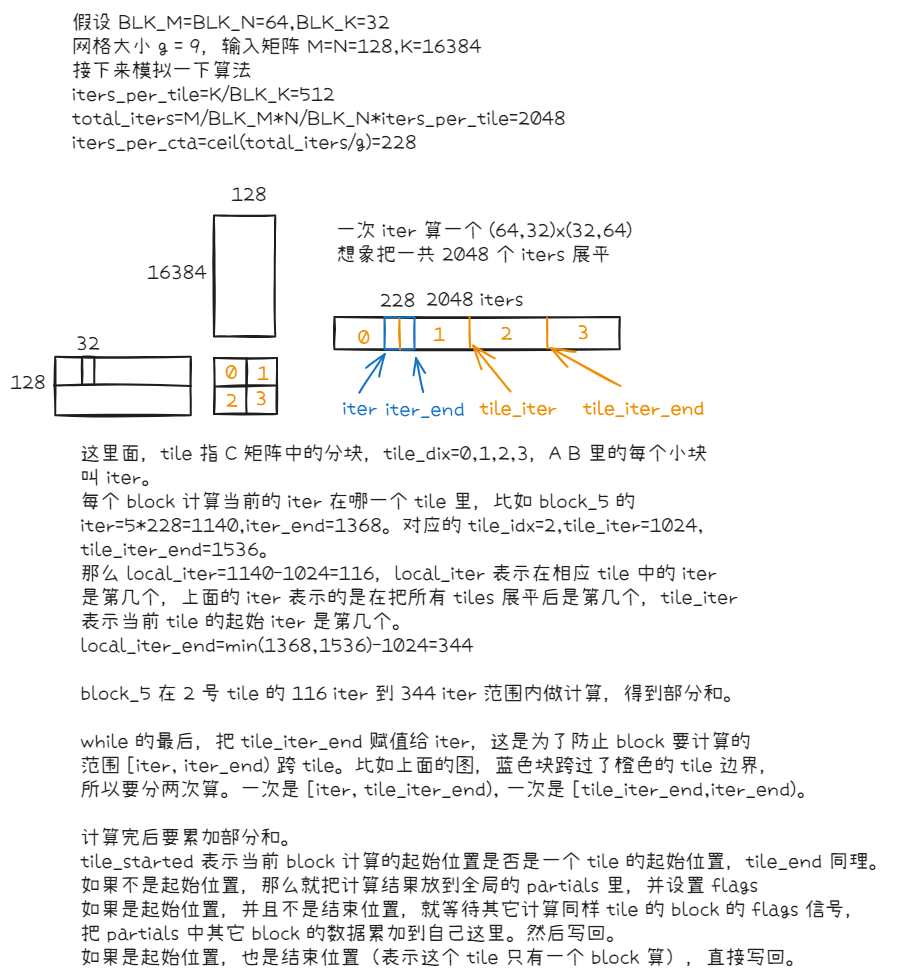
以 M=N=128,K=16384,BLK_M=BLK_N=64,BLK_K=32,g=9 为例,模拟了一下算法的流程。
以输入 384x384x128 为例(论文中的例子),BLK_M=BLK_N=128,BLK_K=4,g=4。
一共 384/128*384/128=9 个 tile,每个 tile 一共 128/4=32 个 iters。总共就是 288 个 iters。相当于每个 block 要算 72 个 iters。由于每个 block 的计算量一样,所以不会有明显的 tail effect。
一个 iters 的计算量是整个 tile 计算量的 1/32,所以 32 路 splitk 也不会有任何 tail effect,但是 fixup(我理解的是同步开销)是 8 倍(感觉不止 8 倍)。而且 streamk 在同步 block 时,由于写入和读取的时间偏差,能更好的掩盖延迟。
当 streamk 的网格大小是 tile 的整数倍时,streamk 就是 splitk(是几倍,就是几路 splitk),如果等于 tile 的数量,streamk 就是普通的 gemm。
streamk 方案的优点是:
- 通信、同步、全局内存读写开销与矩阵规模无关,只与 block 的数量相关。
- 当 tile 的数量大于 block 的数量时(每个 tile 最多由两个 block 计算),几乎没有同步开销。举个例子。4 个 tile,3 个 block。每个 block 都会先算前一部分,再算后一部分并写回。由于每个 block 都是先处理不需要同步的数据,再去等待同步。所以几乎没有等待同步的开销。(画个图好理解一些)
作者的经验:FP64 分块 64x64x16, FP16->FP32 分块 128x128x32。通过一个简单的分析模型选择网格大小,分析模型的细节见附录。
改进:
论文中说 basic Stream-K 会因为 k 偏移导致性能问题(没看出来为啥)。所以提出了两种策略,一种是 DP + one-tile SK,但这样的话,在 one-tile 上的 SK 的同步会有大问题。一种是 two-tile SK + DP,把 DP 的一个 wave 放到 SK 里去算。这样 SK 中,每个 CTA 要算的数据大于一个 tile,少于两个 tile,能更好的隐藏延迟。